

.png)
.png)

It’s funny how in the technology industry we always refer to predominant solutions as legacy. I never hear it used that way outside of IT. Outside of IT, legacy is usually a good thing. In sports, players and teams hope to build a legacy of winning, of making big plays in the clutch! But in IT, calling something legacy makes it sound old and crusty, like it might smell of arthritis cream. Startup products are next generation! They are shiny and limber, with no need of medicinal ointments!
Truth be told, the startups do have cause to strut around a bit, as that’s where a lot of the innovation happens. Without a large install base to be concerned about, they are free to chart a new path. This is not to say that the large, predominant vendors don’t innovate, just that the more disruptive innovations often come from startups.
One area of innovation that Prescriptive is hyper focused on, is Data Management. Startups and incumbent vendors alike are developing and expanding their capabilities so that they can support the Data Management needs of the modern enterprise. Backup vendors are transitioning to a more comprehensive data management platform. Storage vendors are doing the same thing, recognizing that they need to provide more than just reliable, high performing data repositories. Organizations are looking for solutions that help them better manage the data, that take into account that data is now distributed outside of the data center.
This is a long time coming as the sad truth is, in most organizations, no one has been managing the data. The storage guy is primarily focused on making sure your data is accessible, that you don’t run out of space and no one is complaining about performance. If they’ve got any time left after that, they’re handed the backups or system admin responsibilities.
This is also not the first attempt to go down this path. Years ago “Legacy” archiving solutions were supposed to allow organizations to get a handle on their data. Every storage vendor was talking about Information Lifecycle Management. But then SATA drives came along and made it affordable to indiscriminately store everything. Block based or sub LUN tiering was introduced so that you could move the least frequently accessed data to lower cost disk. Yay! We still didn’t have to know anything about our data! We could continue indiscriminately storing it in piles and backing it all up in bigger piles!
So, what’s different now?
Three major developments have made now the right time to get serious about data management.
- Organizations have discovered that there can be a lot of value in data that was once either discarded immediately or shoved off to the cheapest storage, never to be accessed again. Methods are now available to process vast amounts of unstructured data and do it cost effectively.
- Data Management challenges have grown larger and more complex. Data is no longer centralized in the data center, it’s distributed across end user devices and in the cloud. Typically, organizations don’t own the end devices and have little awareness of what data they hold. Even in the cloud, we’re not talking about just the authorized sources like your CRM, we’re talking about unauthorized sources that users leverage because it’s easy. With the emergence of Ransomware, backups are now part of the security discussion and often serve as the last line of defense. On the compliance front, you have more regulations than ever. Lastly, the amount of data organizations have to account for continues to grow exponentially.
- Thankfully the last development is not another challenge but advanced solutions that can address these problems. Over the last several years, the software has dramatically improved. Practical, cost effective solutions, are now available to help organizations gain insight into and take control of their data.
Data Management Platforms
There is a convergence going on where backup and storage technologies are expanding into new areas. What was once just a backup solution may now provide archiving, advanced disaster recovery, and multiple protection methods, where the software serves as the control mechanism but doesn’t actually perform the backup. The storage vendors are moving from selling boxes to selling solutions that not only house data but protect and manage it, no matter where it is physically stored.
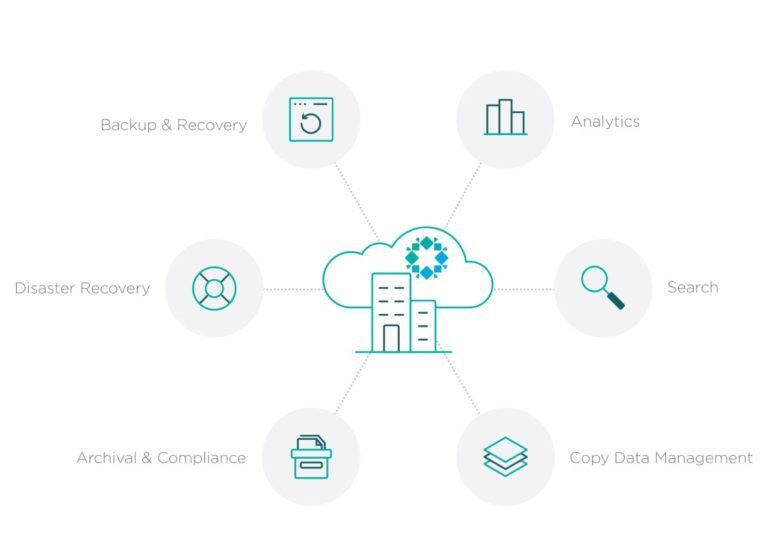
The point is, you need to focus on what you are trying to accomplish and not rely on how a product is categorized. Just because it isn’t called a Data Management Platform doesn’t mean it can’t be used to solve data management problems. At the same time, calling it a Data Management Platform doesn’t mean that it is. Think back to when virtualized became the king of the buzzwords. Marketing teams worked day and night rebranding their products as virtual, often without a single line of product code being changed!
So what are the key capabilities of Data Management Platforms and things you should consider when evaluating them?
Data Protection
Backup and Recovery, Replication and DR. These capabilities may be inherent in the solutions themselves or they may serve as the control plane and management overlay for native tools. In many cases they may do both, providing a set of core capabilities within the product itself and the ability to work with snapshot, cloning or replication features built into the source hardware and software. Consider what it would be like to have one solution that is responsible for all your data protection, not just one aspect. I use this tool for my backups, this tool for my snapshots and this tool over here for DR. I have no idea if I am protecting the data appropriately but I sure am busy! Data Management platforms are intended to cover the spectrum of protection and recovery requirements in a greatly simplified way.
Coverage
You need to understand what you are trying to protect and manage. Does the solution protect on premise and cloud? How much of your environment can it handle, does it work with your existing applications and data repositories? Can it handle remote offices? Does it handle end user devices? You may not find a single solution that does it all or does it all well but the more closely it aligns with your specific needs, the better. Pay close attention to the part where I said and does it all well. Try not to fall in love with one area it does well and forget to validate the other areas you will expect it to cover. For example, let’s say you just can’t get away from tape right now, you gotta have it. You’re in luck, the solution you are evaluating supports tape. Not until after the purchase, do you discover it can write to tape but it doesn’t provide a vaulting option, so now you’re manually tracking tapes and forcing the library to spit them out one at a time. Even worse, you find that it does support tape, just not your tape library! And worst of all, you now realize you probably could have used cloud instead of tape if you had understood the limitation from the beginning and incorporated cloud storage into the budget. Details matter in what we do.
Archiving
Some of you may cringe at the very mention of archiving. As I said in my previous post on the subject, early implementations often failed to meet expectations. That being said, archiving is more important than ever. In the past, determining the cost of the infrequently accessed data was a complex exercise but the cloud folks have solved that for you by providing a bill. You see the costs every month. Aha! But don’t the cloud providers offer archiving? Yes, some of them do and that can be a good option but most organizations don’t store all of their data in a single cloud. There is still a tremendous amount of data on prem and typically distributed across multiple clouds, not just one. You could leverage a separate archiving solution for each and that would be better than if you did nothing but what about when you want to actually use the archive, actually find the data you need? It would be nice if you had a single archive or index that spanned all of your data repositories.
Analytics and Reporting
One of the strongest benefits of a Data Management Platform is they often provide the ability leverage backup data for other purposes such as reporting and analytics. Rather than having separate software and processes for refreshing test and dev environments you can use the backup data you already have. You don’t need a second solution to walk your unstructured data to tell you about it because that information is inherently captured during backups. You can query this data, make copies, write to it or change the data all without impacting production or damaging the backups.
Be Pragmatic
For many organizations it is unlikely you are going to find a single solution that meets all of your needs. Startups tend to be lean and focus heavily on where the biggest market is. That’s appropriate but it often means they can’t cover everything. Incumbent solution providers typically have the broadest base, but may not yet have the “next generation” capabilities that you’re looking for. If you are focused and understand what it is you’re trying to accomplish you can determine the best combination of solutions to meet your needs. This is where Prescriptive can help. We understand data not just storage and backups. We understand the latest technologies and can help you navigate the options, develop the appropriate strategy and ensure it is implemented correctly.
Looking for Expert Advice?
We're happy to help!